
Masinõppemeetodi valiku juures mängivad rolli mitmed aspektid, näiteks see, millised on andmed, millel meetodit rakendada plaanitakse, aga ka see, milliseid ressursse on võimalik mudeli treenimiseks kasutada ning millised on nõuded treenimiskiirusele, treenitud mudeli suurusele või ennustuskiirusele. Lisaks võib olla oluline, et masinõppemudelit saaks lihtsasti tõlgendada ehk mudeli tehtud otsused oleksid selgitatavad.
Otsustuspuul (ingl decision tree) põhinevaid masinõppemeetodeid kasutatakse nii klassifitseerimise (diskreetsete kategooriate ennustamise) kui ka regressiooni (pidevate väärtuste ennustamise) jaoks. Seda tüüpi meetodeid rakendatakse paljudes valdkondades, näiteks linnaelanike eelistatud liikumisviisi ennustamiseks [1]“Smart City Mobility Application—Gradient Boosting Trees for Mobility Prediction and Analysis Based on Crowdsourced Data” (Semanjski 2015) või molekulaarsete deskriptorite valimiseks ravimite väljatöötamisel [2]“Automatic Selection of Molecular Descriptors Using Random Forest: Application to Drug Discovery” (Cano 2017) . Kuidas sellised meetodid töötavad, mis on nende eelised ja puudused ning kuidas nende vahel valida?
Kuidas töötavad erinevad puupõhised algoritmid?
Otsustuspuu
Lihtsaim puupõhine masinõppemeetod on üksik otsustuspuu, mis jõuab ennustuseni sisuliselt sisendi kohta jah-ei küsimusi küsides. Mudeli ehitamiseks otsib algoritm igal sammul küsimust, mis annab otsuse tegemiseks kõige enam infot.
Otsustuspuu treenimine lõpeb kas siis, kui mudel on suutnud perfektselt ära jaotada kogu treeningandmed, või siis, kui mudel on jõudnud talle seatud peatumistingimusteni. Näiteks saab piirata puu sügavust ehk seda, kui mitme küsimusega peab vastuseni jõudma. Mida sügavam on otsustuspuu, seda komplekssem on mudel ja seda paremini jäljendab mudel treeningandmeid, ent liiga täpne jäljendamine ehk ülesobitamine (ingl overfitting) viib kehvemate ennustusteni uutel andmetel.
Joonis 1. Otsustuspuu
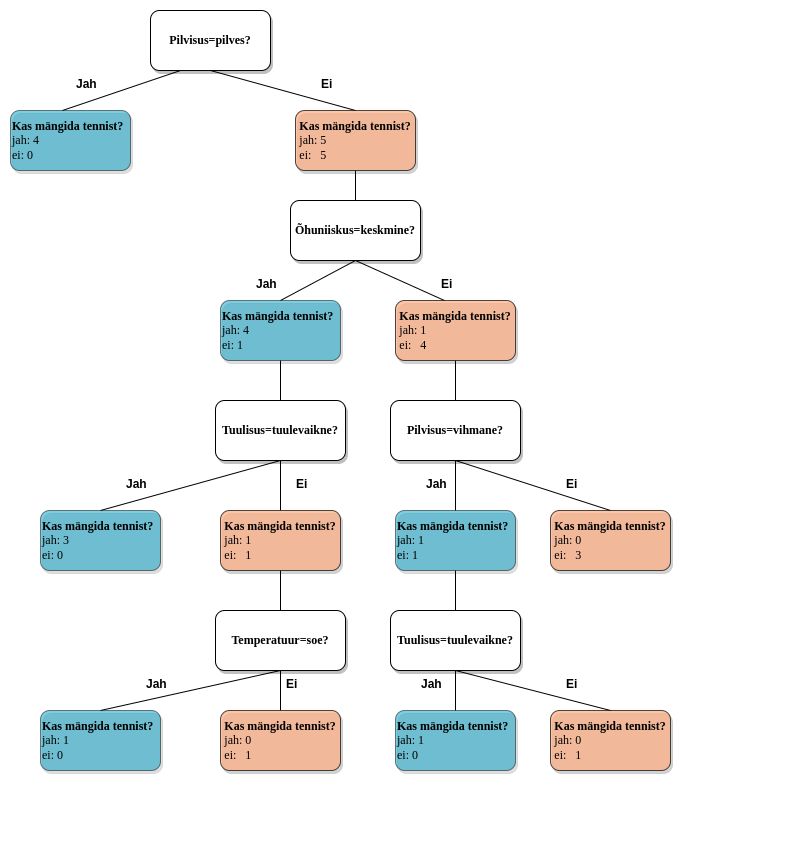
Joonisel 1 on toodud näide otsustuspuust, mis saab sisendiks ilmaolusid kirjeldavate tunnuste väärtused. Graafil ülalt alla liikudes on selge, millistel juhtudel jõuab mudel ühe või teise ennustuseni (kas mängida tennist või mitte). Selline justkui tagurpidi pööratud puu, mille juur on üleval ja lehed all, on levinud viis otsustuspuude kujutamiseks. Otsustuspuude kontekstis tähendab juur esimest otsustuspunkti, millest erinevad teekonnad lehtedeni edasi hargnema hakkavad, ning lehed on graafi lõppsõlmed, mis määravad mudeli ennustuse. Klassifitseerimisülesande puhul saab ennustuseks see klass, mille treeningnäiteid kuulub antud lehte rohkem.
| Pilvisus | Temperatuur | Niiskus | Tuulisus | Kas mängida tennist? | |
|---|---|---|---|---|---|
| 0 | Päikseline | Palav | Kõrge | Tuulevaikne | Ei |
| 1 | Päikseline | Palav | Kõrge | Tuuline | Ei |
| 2 | Pilves | Palav | Kõrge | Tuulevaikne | Jah |
| 3 | Vihmane | Soe | Kõrge | Tuulevaikne | Jah |
| 4 | Vihmane | Jahe | Keskmine | Tuulevaikne | Jah |
| 5 | Vihmane | Jahe | Keskmine | Tuuline | Ei |
| 6 | Pilves | Jahe | Keskmine | Tuuline | Jah |
| 7 | Päikseline | Soe | Kõrge | Tuulevaikne | Ei |
| 8 | Päikseline | Jahe | Keskmine | Tuulevaikne | Jah |
| 9 | Vihmane | Soe | Keskmine | Tuulevaikne | Jah |
| 10 | Päikseline | Soe | Keskmine | Tuuline | Jah |
| 11 | Pilves | Soe | Kõrge | Tuuline | Jah |
| 12 | Pilves | Palav | Keskmine | Tuulevaikne | Jah |
| 13 | Vihmane | Soe | Kõrge | Tuuline | Ei |
Joons 2. Andmestik
Näitemudeli treenimiseks kasutatud väike näidisandmestik on toodud joonisel 2. Tunnused on siin pilvisus, temperatuur, niiskus ja tuulisus. Ennustatav muutuja on kategooriline “Kas mängida tennist?”, mistõttu on tegemist klassifitseerimisülesandega.
Parima küsimuse leidmine
Algoritm otsib igal sammul küsimust (tunnust ja väärtust), mis kõige paremini eraldaks erinevatesse klassidesse kuuluvad treeningnäited üksteisest. Selleks proovitakse läbi palju erinevaid võimalikke küsimusi ja valitakse nende hulgast parim, seejuures on valiku tegemiseks mitu võimalust. Näiteks kasutatakse küsimuse headuse hindamiseks Gini ebapuhtust (ingl Gini impurity). See on funktsioon, mis näitab, kui tõenäoline on, et andmepunkt saab vale prognoosi, kui prognoosida suvaliselt klasside jaotuste põhjal – mida madalam väärtus, seda parem küsimus. Gini ebapuhtus on minimaalne siis, kui küsimus jaotab erinevad klassid üksteisest täielikult ja selle tulemusena tekivad n-ö puhtad lehed (ingl pure nodes), millega puu antud haru lõpeb.
Füüsikatunnist võib olla tuttav entroopia mõiste, mis mõõdab süsteemi korratust või korrastamatust. Sarnaselt on entroopia mõiste kasutusel informatsiooniteoorias, kus see mõõdab andmete ebamäärasust. Otsustuspuu treenimise käigus kasutatakse ka entroopiat headuse kriteeriumina. Sellisel juhul püüab algoritm leida sellise küsimuse, millele vastamine vähendaks entroopiat ehk teisisõnu annaks uut informatsiooni võimalikult palju.
Otsustuspuud teisteks ülesanneteks
Eeltoodud näites oli otsustuspuu ülesandeks kahe klassiga ehk binaarne klassifitseerimine, kuid otsustuspuid on võimalik sama lihtsasti kasutada ka enamate klasside puhul. Lisaks on selle meetodiga võimalik lahendada regressiooniülesandeid, millisel juhul nimetatakse treenitud mudelit ka regressioonipuuks.
Kuna regressiooni puhul ennustatakse pidevaid väärtusi, tuleb kasutada teistsuguseid kriteeriume parima küsimuse leidmiseks. Üks valik on näiteks Mean Squared Error ehk MSE, mille eesmärk on minimeerida erinevust ennustatud ja tegelike väärtuste vahel. Selleks leitakse, millise küsimuse puhul jagunevad treeningnäited nii, et erinevus ühte gruppi jäävate näidete keskmise väärtuse ja nende tegelike väärtuste vahel oleks minimaalne.
Eelised ja puudused

Lihtsasti tõlgendatav
Otsustuspuu suureks eeliseks täpsuse poolest võimekamate konkurentide ees on selle tõlgendatavus: puumudeli saab üks-ühele visualiseerida graafina, millelt on lihtne välja lugeda, kuidas mudel otsuseni jõudis – vähemalt seni, kuni otsustuspuu on hoomatava sügavusega.
Ei vaja palju tööd andmete ettevalmistamiseks
Otsustuspuu suudab toime tulla erinevate andmetüüpidega, näiteks nii arvuliste kui kategooriliste väärtustega (see võib siiski sõltuda implementatsioonist), ning ei nõua erinevalt mõnest teisest meetodist andmete eelnevat normaliseerimist.

Oht treeningandmetel ülesobitada
Nagu eespool mainitud, on otsustuspuul oht treeningandmed detailideni „pähe õppida”, mistõttu väheneb mudeli üldistusvõime ehk oskus teha kvaliteetseid ennustusi uutele andmetele.
Astmelised, mitte sujuvad ennustused
Kuna otsustuspuu hargnemiskohtades sõltub haru valimine küsimusest (nt “Kas temperatuur on <20°C?”) , võib juhtuda, et tunnuse väärtuse oluline suurenemine (nt 10 kraadilt 19 kraadile) ei muuda otsustuspuu ennustust, aga seejärel väike lisa (nt 19-lt 20-le) pöörab ennustuse vastupidiseks.
Kergelt mõjutatav muutustest treeningandmestikus
Treenitud mudelid võivad olla üksteisest väga erinevad, isegi kui treeningandmestikud on peaaegu identsed – väikestel muutustel andmestikus võib olla suur mõju lõppmudeli struktuurile ja seeläbi ka ennustustele.
Otsustusmets aka juhuslik mets
Otsustusmets (ingl random forest) liigitub ansambelõppe (ingl ensemble learning) alla, kus lõppennustus moodustub kombinatsioonina mitme mudeli ennustusest. Otsustusmetsa (joonis 3) puhul kuulub ansamblisse hulk otsustuspuid, millest igaüks on treenitud erineval bootstrap’itud valimil treeningandmestikust.
Bootstrappimine tähendab, et originaalsest treeningandmestikust suurusega n võetakse juhuslikult n treeningnäidet, seejuures pärast iga võtmist asetatakse valitud näide ka tagasi – seega võib üks ja sama näide valimisse jõuda mitu korda, samal ajal mõni teine sealt üldse puududa.
Lisaks on iga otsustuspuu treenimisel piiratud arv juhuslikult valitud tunnuseid, mille alusel teha puus järgmine jaotus ehk küsida järgmine küsimus. Mõlema mainitud eripära eesmärk on lisada mudelitesse juhuslikkust, mille abil suureneb erinevus ansamblisse kuuluvate üksikute otsustuspuude vahel. Kui lõppennustuse saamiseks nende erinevate mudelite ennustused kombineeritakse, saavutatakse parem üldistusvõime kui üksikut otsustuspuud kasutades. Teisisõnu – väheneb risk ülesobitamiseks treeningandmestikul.
Klassifitseerimisülesande puhul valitakse lõppennustuseks see, mis on kõigi ansamblisse kuuluvate mudelite ennustuste seas ülekaalus, regressiooniülesande puhul saab lõppennustuseks kõigi mudelite ennustuste keskmine väärtus.

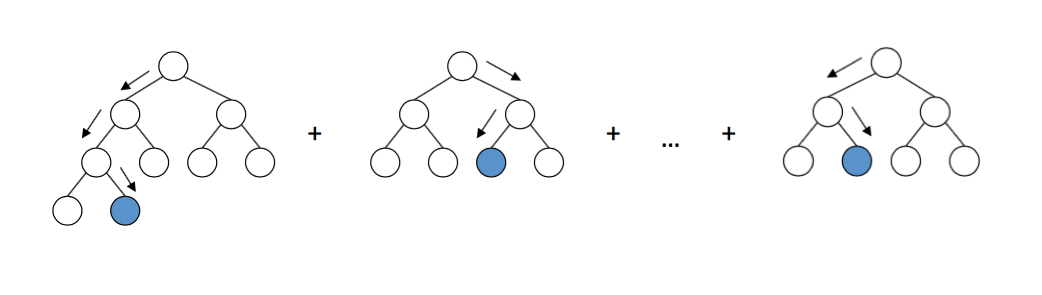
Joonis 3. Otsustusmets
Allikas: Random Forest Machine Learning in R, Python and SQL – Part 1
Eelised ja puudused
Ei vaja palju tööd andmete ettevalmistamiseks
Kuna otsustusmets koosneb otsustuspuudest, kehtib sama eelis vähese nõudlikkuse kohta andmete ettevalmistamise suhtes ka siin.
Parem üldistusvõime kui üksikul otsustuspuul
Märkimisväärne erinevus on eelmainitud parem üldistusvõime uutel andmetel, mis saavutatakse hulga mudelite ansamblisse koondamise ja nende ennustuste kombineerimise abil.
Parem töökindlus suure arvu tunnuste korral
Otsustusmets tuleb paremini toime andmestikega, kus on suhteliselt palju tunnuseid – üksik otsustuspuu on sellisel juhul eriti aldis ülesobitamisele.
Raskemini tõlgendatav kui otsustuspuu
Kuna lõppennustuses osalevad kõik ansambli mudelid (neid võib olla sadades või enamgi), ei ole iga mudeli graafina kujutamine ja sealt ennustuskäigu välja lugemine enam nii lihtne. Analüüsides iga üksiku mudeli struktuuri, on võimalik teha järeldusi selle kohta, millised tunnused treeningandmestikus mõjutasid ansamblit kokkuvõttes enim, kuid üksikule uuele näitele tehtud ennustust on siiski keeruline lahti seletada. Selliste “musta kasti” tüüpi (ingl black box) mudelite ennustuste selgitamine on omaette uurimissuund [3]“Interpreting Blackbox Models via Model Extraction” (Bastani 2017) [4]“Interpreting Random Forest Classification Models Using a Feature Contribution Method” (Palczewska 2014) .
Ressursinõudlikum
Ansambelõppemudelitega kaasneb ka küsimus arvutuslike ressursside kohta. Näiteks saja mudeliga otsustusmets vajab rohkem salvestusruumi kui üksik otsustuspuu. Samuti muutub treenimine ja ennustamine aeglasemaks. Otsustusmetsa kasuks räägib siiski see, et ansamblisse kuuluvaid mudeleid saab treenida ja hiljem ka rakendada üksteisest sõltumatult, mistõttu on võimalik neid protsesse paralleliseerida.
Gradient boosting
Gradient boosting on teine ansambelõppe alla kuuluv masinõppemeetod, mis koosneb sageli samuti otsustuspuudest. Erinevalt otsustusmetsa meetodist toimub siin mudelite treenimine järjestikuselt, mitte paralleelselt – see tähendab, et iga järgnev mudel sõltub eelmistest. Ansamblit rakendades moodustub lõppennustus kõigi ansamblisse kuuluvate mudelite väljundite kokkuliitmise teel (joonis 4).

Joonis 4. Gradient boosting
Allikas: http://arogozhnikov.github.io/images/gbdt_attractive_picture.png
Boosting-meetodite põhiidee seisneb selles, et treenitakse hulk “nõrku ennustajaid” (ingl weak learners), kusjuures iga järgneva mudeli treenimisel püütakse parandada eelnevate mudelite vigu. Eesmärk on saavutada nõrkade ennustajate nutika kombineerimise tulemusena tugev ennustaja. Nõrgaks ennustajaks loetakse masinõppemudelit, mille ennustustäpsus on vaid veidi parem juhuslikust ennustamisest. Näiteks kahe klassiga klassifitseerimise puhul oleks juhusliku ennustaja täpsus 50%, seega nõrga ennustaja täpsus peab olema sellest kõrgem.
Gradientlaskumine
Millele viitab sõna gradient meetodi nimes? Gradientlaskumine (ingl gradient descent) on masinõppes levinud optimeerimisalgoritm, mille eesmärk on minimeerida kahju ehk erinevust ennustatud ja tegelike väärtuste vahel. Tehisnärvivõrkudes kasutatakse gradientlaskumist mudeli parameetrite uuendamiseks treenimise käigus. Selleks leitakse, kuidas iga parameeter mõjutab kahju väärtust, arvutades kahju leidmiseks kasutatava funktsiooni ehk kaofunktsiooni osatuletised iga parameetri suhtes. Need osatuletised moodustavadki gradiendi ning näitavad, millises suunas tuleks parameetreid muuta, et kaofunktsioon kõige järsemalt kasvaks. Kuna eesmärk on kaofunktsiooni mitte maksimeerida, vaid minimeerida (sellest ka sõna “laskumine”), siis muudetakse parameetreid gradiendile vastupidises suunas.
Üks varasemaid boosting-meetodeid AdaBoost kasutas järjestikuste mudelite treenimiseks treeningnäidete kaalumise meetodit, mille abil suunata järgneva mudeli treenimisel rohkem tähelepanu keerulistele juhtudele. Gradient boosting meetodis kasutatakse aga kaalumise asemel gradientlaskumist. Sellega leitakse, kuidas senise ansambli ennustused mõjutavad kaofunktsiooni, ning järgmise mudeli treenimisel püütakse selle ennustusi suunata vastavalt gradiendile.
Eelised ja puudused
Sama hea või parem täpsus kui otsustusmetsal
Gradient boosting mudelid on võrdlustes näidanud sama head või paremat täpsust kui otsustusmetsa mudelid, mis kinnitab boosting-meetodi efektiivsust [5]“An Up-to-Date Comparison of State-of-the-Art Classification Algorithms” (Zhang 2017) [6]“Prediction of Lung Cancer Patient Survival via Supervised Machine Learning Classification Techniques” (Lynch 2017) .
Kiirem ennustusprotsess kui otsustusmetsal
Kuna gradient boosting ansambel koosneb enamasti väiksematest mudelitest kui otsustusmets, on sellega lõppennustuseni jõudmine kiirem. See võimaldab uutele näidetele kiiremini reageerida ja ennustusi väljastada. See omadus võib osutuda väga tähtsaks reaalajas kasutatavate süsteemide puhul.
Raskemini tõlgendatav kui otsustuspuu
Sarnaselt otsustusmetsale on ennustused raskemini selgitatavad kui üksiku otsutuspuu puhul, sest lõppennustus moodustub paljude mudelite ennustuste kombineerimise teel.
Tundlikkus erandlike treeningnäidete suhtes
Gradient boosting meetod on erandlike treeningnäidete suhtes tundlikum, sest algoritm püüab iga järgneva mudeliga üha enam raskeid juhtumeid õigesti ennustada, mis võib viia soovimatute tulemusteni. Samal põhjusel mõjutavad algoritmi negatiivselt valesti märgendatud treeningandmed.
Ajamahukam treenimine
Erinevalt otsustusmetsast ei ole gradient boosting ansamblisse kuuluvaid mudeleid võimalik paralleelselt treenida, sest mudelid on üksteisest sõltuvad.
Kuidas puupõhiseid meetodeid rakendada?
Nii otsustuspuu, otsustusmetsa kui ka gradient boosting algoritme saab üles seada, kasutades olemasolevaid teeke. Näiteks gradient boosting meetodist on loodud erinevaid variatsioone, millel igal omad eelised ja edasiarendused.
Scikit-learn on laialt kasutatav Pythoni teek, mille abil on võimalik rakendada paljusid masinõppealgoritme. Sellel lehel antakse lühike ülevaade otsustuspuudest koos praktiliste nõuannetega Scikit-learni implementatsiooni kasutamiseks.
Lisaks tavalisele otsustuspuule toetab Scikit-learn ka otsustusmetsa ja gradient boosting meetodite implementeerimist – siin kirjeldatakse Scikit-learnis saadaolevaid ansambelõppemeetodeid ja tuuakse näiteid erinevate meetodite kasutamise kohta.
Nimi XGBoost on lühend fraasist eXtreme Gradient Boosting, mille peamised eelised on kiirus ja skaleeritavus. XGBoost kasutab spetsiaalset algoritmi, mis töötab hästi hõredatel andmetel (ingl sparse data) ehk andmetel, kus on palju puuduvaid väärtusi või nulle, ning kasutab paralleliseerimist ühe puu treenimise lõikes.
LightGBM teegis on astutud veel üks samm edasi kiirema treenimise suunas, kasutades kaht uuenduslikku meetodit: gradiendipõhine treeningandmete valik ja üksteist välistavate tunnuste ühendamine. Esimese eesmärk on vähendada kirjete arvu, millel üksikuid mudeleid treenitakse, ning teise eesmärk on vähendada tunnuste arvu, mille vahel treenitav mudel saab valida. Lisaks treenitakse LightGBM-is mudeleid mitte kihthaaval, vaid lehthaaval ehk järgmine sõlm, millest puu edasi hargneb, võib asuda ükskõik millisel sügavusel – peaasi, et sealt jätkamine tooks võimalikult palju kasu.
CatBoost (fraasist categorical boosting) toetab mudelite treenimist nii CPU kui ka GPU toel, pakkudes viimasega võimalust ressursside olemasolul treenimist kiirendada. Nagu teegi nimi viitab, on selle implementatsiooni juures pandud rõhku kategooriliste tunnuste toetamisele – nimelt võib CatBoosti rakendada otse andmestikul, kus on kategoorilisi tunnuseid, ilma et kasutajal oleks tarvis need ise sobivale kujule teisendada. Samuti on selle teegi puhul tõenäoline, et hüperparameetrite (kasutaja poolt seadistatavate parameetrite) vaikeväärtused töötavad juba üsna hästi, sest need leitakse vastavalt ülesandele, andmestiku suurusele ja muudele näitajatele.
Kokkuvõte
Puupõhised masinõppemeetodid on leidnud ja leiavad endiselt kasutust paljudes valdkondades, alates finantsvaldkonnas krediidiriski hindamisest kuni transpordis reaalajas liiklusriskide hindamiseni ja müügivaldkonnas tulemusnäitajate ennustamiseni. STACCis on otsustusmetsa meetodi abil ennustatud näiteks museaalide säilivust, mille kohta saab pikemalt lugeda siit.
Igal masinõppemeetodil on omad iseärasused, mistõttu tasub muu hulgas läbi mõelda, millised on andmed, nõuded treenitud mudelile ning saadaolevad ressursid. Seejärel saab asuda rakendama nendest sobivamaid ja avastada, mida masinõpe andmetega teha suudab.
Märksõnad: masinõpe, masinõppemeetodid, otsustuspuu, puumudelid, otsustusmets, juhuslik mets, gradient boosting, XGBoost, Scikit-learn, LightGBM, CatBoost, ansambelõpe.
Viited




{kind=link}