
Policymaking requires access to high-quality, relevant information. But how can critical data be identified amidst an ever-growing volume of content? This challenge prompted the Government Office of Estonia to commission STACC and TEXTA to develop a solution. The result: a prototype of a semantic search tool that enables civil servants to find information faster, easier, and with greater accuracy.
Decision-making requires a clear data overview
Each year, thousands of Estonian-language studies, reports, laws, and other documents are created. The vast volume and scattered nature of these valuable resources make finding relevant information time-consuming and increase the risk of overlooking critical insights during the policymaking process. Given that policies impact society as a whole, improving decision-making workflows has far-reaching benefits.
To address this challenge, the Government Office commissioned a prototype for a semantic text search application. The idea is straightforward: an advanced language model analyzes user queries, retrieves relevant sources, and compiles clear responses. For example, during the evaluation of a draft law, the tool can quickly provide an overview of pertinent public studies. The initial target group includes all those involved in preparing policy decisions.
GPT-4o was the optimal choice
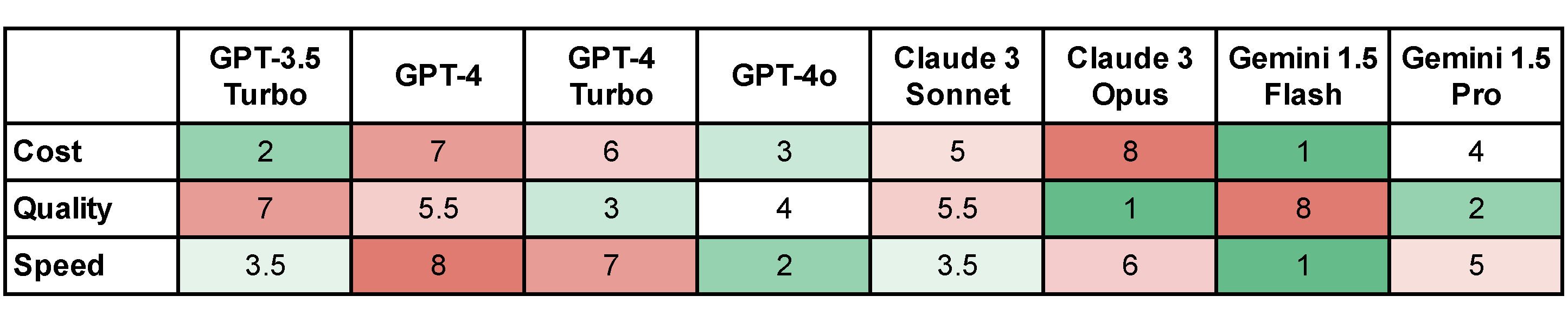
Which language model best meets user needs? We evaluated eight different models to identify the optimal balance of cost, speed, and quality. Based on user scenarios, the assessment included summary generation and the ability of large language models (LLMs) to answer factual questions. Using Estonian Public Broadcasting articles as a test dataset, we established evaluation criteria and ranked the models. The results pointed to GPT-4o as the recommended choice for the application.
We conducted an in-depth analysis of the client’s use cases, assessing feasibility and determining user needs and workflows. The most suitable solution proved to be retrieval-augmented generation (RAG), where the system retrieves relevant text segments from documents based on user queries and passes them to the language model to generate responses. This approach mitigates common LLM issues, such as “hallucinations,” where the model might provide inaccurate information.
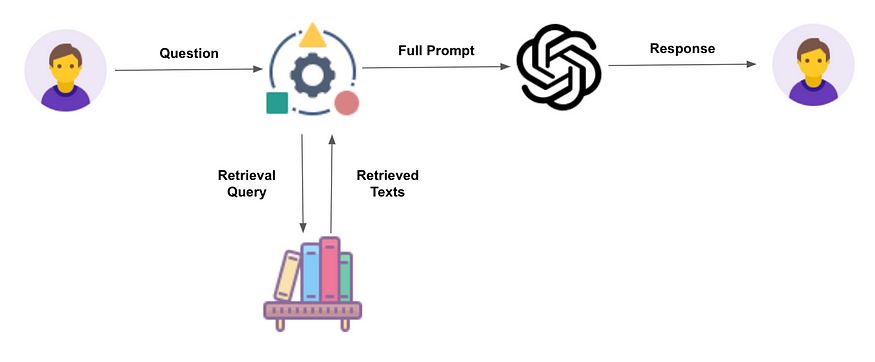
Making search smarter
Developing the prototype involved extensive data processing to ensure the search tool is both precise and efficient. Using references provided by the client, we compiled the necessary datasets from the internet and standardized them into a uniform format. Before integrating the data into the database, we segmented and vectorized the collected files. This preprocessing step was crucial, as the input length for language models is limited and directly affects operational costs.
Next, we developed the semantic text search prototype along with its software and user interface. Users can specify time periods and sources when submitting queries. The tool provides two types of responses: one based on the model’s internal knowledge and another derived from the analyzed sources. For transparency, the tool displays citations of the sources used in generating the answers.
A fully operational prototype
This semantic search application stands out due to its extensive Estonian-language knowledge base, long-term testing period, and broad potential for future use. The prototype is currently being used by a test group, and we are collecting usage statistics and feedback to further develop and refine the application.
Future project phases aim to map public sector text data comprehensively and create a robust semantic text search application tailored to the Estonian language and built on local language technology tools. The final application would broadly support public sector officials, facilitating the automation of preparatory tasks for decision-making across government agencies and local authorities.
“The prototype was developed through a procurement process in collaboration with TEXTA and STACC, who demonstrated a clear understanding of our needs, incorporated them into the design, and remained focused on achieving the stated goals. The result is a well-functioning prototype, carefully aligned with defined limitations. We plan to develop it further in the near future to create a solution that enhances policymaking efficiency. TEXTA and STACC were undeniably competent partners, and the simplicity of the user interface received very positive feedback from the prototype testers.”
— Erik Ernits, project manager of the Government Office of Estonia
The activities and projects of the Government Office Innovation Fund are funded by the European Union Cohesion Policy 2021-2027 measure “Enhancing Public Sector Innovation Capacity”.
Sources:
[1] Retrieval-Augmented Generation (RAG), pvml.com
Cover photo: Ametniku tööruum, ERA.5637.0.501762, National Archives Photo Database



